![[알고리즘] 스트링 처리 알고리즘 | 허프만 코드, 허프만 알고리즘](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FzukMk%2FbtrRmU9QpVS%2FsMb3r60cwlYkx4EeNlJb20%2Fimg.png)
압축이란 파일의 크기를 줄이는 방법을 의미한다. 즉, 시간 보다는 공간을 절약하는 방법에 대해 연구한다.
대부분의 컴퓨터 화일에서는 데이터가 중복되어 있다고 착안하고 있다.
압축을 하게되면 한정된 컴퓨터자원을 효율적으로 사용할 수 있다.
1) 런-길이 인코딩
화일에서 기본적인 중복은 같은 문자가 연속적으로 나타나는 것이다.
하나 예시를 들어보자면, AAAABBCCCCC = 4A2B5C 와 같이 표현할 수 있다.
위와 같이 동일한 문자가 여러개 나올 경우 숫자와 문자 쌍으로 화일을 압축하는 기법을
'런-길이 인코딩'이라고 한다. 그러나 실제 문서에서는 같은 문자가 여러번 연속해서 나오는 경우가 많지 않기에
런-길이 인코딩은 주로 이진수로 표현되는 비트맵 이미지를 압축하는데 사용된다.
예를들어 이진수 0000001111000 은 '6 4 3' 으로 표현될 수 있다.
이 인코딩 기법은 숫자와 문자가 혼합된 텍스트 파일에서는 적용할 수 없다는 단점이 있으므로
텍스트에서 드물게 나타나는 문자를 탈출문자로 사용해 탈출 순차를 만들어주면 된다.
탈출 순차는 탈출문자, 개수를 표현하는 알파벳과 한 개의 반복 문자로 구성되어 있다.
예를 들어, AAAABBCCCCC는 QDABBQEC로 표현한다.
또, 영문자 Q는 'Q<space>' 로 표현하고, 26개가 넘는 문자열은 26개씩 나누어서 표현한다.
예를 들어 50개의 B가 연속으로 나올 경우, QZBQXB로 표현한다.
2) 가변-길이 인코딩
자주 나타나는 문자에는 적은 비트를 사용하고 드물게 나타나는 문자에는 많은 비트를 사용하여
인코드 하는 압축기법을 가변-길이 인코딩이라고 한다.
예를들어 ABRACADABRA라는 문자열에 대해
A는 00001로 B는 00010로, C는 00011로, D는 00100으로, R은 10010으로 코드를 할당할 경우
다음과 같이 인코드 된다.
0000100010100100000100011000010010000001000101001000001
이 문자열을 디코드하려면 한 번에 다섯 비트씩 읽어서 다섯 비트에 해당되는 문자를 반환하면 된다.
그런데 C D는 한 번 밖에 나오지 않았는데, A와 같은 길이로 인코드되고 있으므로 공간의 낭비가 발생할 수 있다.
따라서 문자의 빈도수를 계산한 다음 많이 나온 문자를 짧은 비트로 코드를 할당하고,
적게 나온 문자를 긴 비트로 코드를 할당하면 공간을 절약할 수 있게된다.
자, ABRACADABRA 를 빈도수 계산하여 인코드해보자.
0 1 01 0 10 0 11 0 1 01 0
위에서 사용한 문자 코드는 하나의 문자 코드가 다른 문자 코드의 접두부와 일치하는 경우가 발생한다.
즉, 구분 문자가 없다면 위에서 01이 어떤 문자를 나타내는건지 알 수 없다. 그렇기에 반드시 구분 문자를 사용해야 한다.
하지만...구분 문자를 사용하는 것은 공간의 낭비를 초래한다.
여기서 발상하여 하나의 문자 코드가 다른 문자코드의 접두부와 일치하지 않는다면 구분 문자를 사용할 필요도 없다.
A: 11
B: 00
C: 010
D: 10
R: 011 로 코드를 할당하고 난 뒤
위 문자열을 인코드하면 다음과 같이 25 비트의 스트링이 된다.
1100011110101110110001111
각 문자에 할당하는 코드를 다르게 해주면 (과정 생략) 23비트 스트링까지도 가능하다.
이를 가능하게 하는 자료구조는 트라이 이다!!
트라이를 사용하면 비트 스트링을 디코드 할 수 있다.
트리구조를 사용하는 알고리즘이 바로 허프만 코드 알고리즘이다.
여러개의 트라이 중에서 어떤 것이 가장 효율적인지 결정하는 방법인 허프만 인코딩에대해 알아보자.
발생 빈도가 가장 낮은 두 문자를 선택해서 하나로 합친다.
왼쪽은 빈도수가 낮고 오른쪽은 높다.
빈도수가 같은 것 중에서는 작은 것을 우선적으로 연결한다.
트리가 생성되면 차례대로 0과 1을 부여한다.
이렇게 인코딩된 메세지 길이는 허프만 빈도수 트리의 가중치 외부 경로길이와 같게 되는데,
동일한 빈도수를 가지는 경우 허프만 트리보다 가중치 외부 경로 길이가 짧은 트리는 구할 수 없다.
이로써 허프만 트리가 최적해가 된다.

허프만 코드
허프만 알고리즘에 의해 생성된 최적 이진코드
허프만 알고리즘
허프만 코드에 해당하는 최적 이진트리를 구축하는 탐욕 알고리즘

허프만 알고리즘: 탐욕 알고리즘
n: 주어진 데이터 파일 내 문자의 개수
PQ: 빈도수가 낮은 노드를 먼저 리턴하는 우선순위 큐(min-heap)
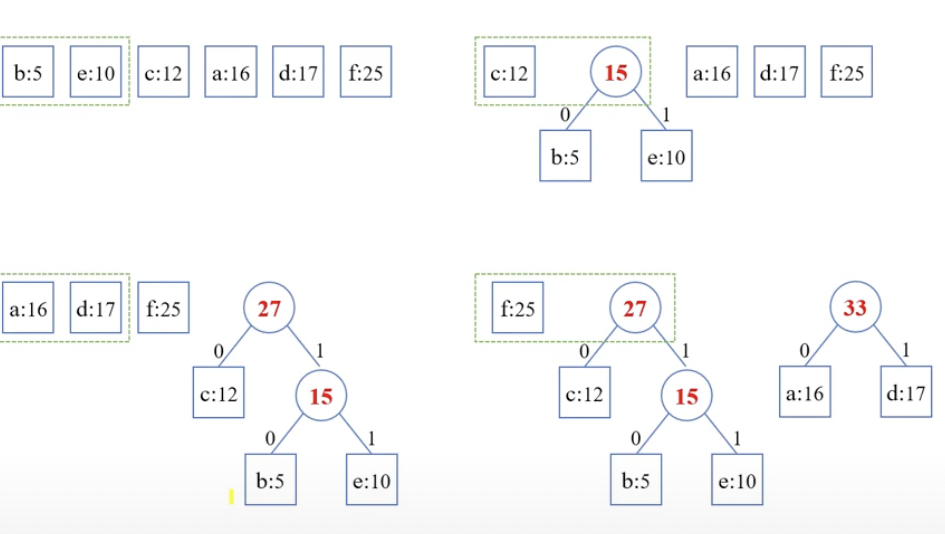
문자의 빈도수를 오름차순으로 정렬한 후 앞에서부터 정렬한다
맨 앞 두 개(빈도수가 가장 작은 문자) 를 연결하며 위처럼 허프만 알고리즘을 이용하면 된다.
'전공 수업 CS > algorithms' 카테고리의 다른 글
| [알고리즘] 욕심쟁이 알고리즘 | 그리디 알고리즘(Greedy Algorithm)동적 계획법을 공부하다가 궁금해진 알고리즘 (0) | 2022.11.16 |
|---|---|
| [알고리즘] 동적 계획법 | 다이나믹 프로그래밍 ( Dynamic Programing) (0) | 2022.11.16 |
| [알고리즘] 스트링 처리 알고리즘 | 화일 압축 알고리즘 | 허프만 인코딩 (0) | 2022.11.16 |
| [알고리즘] 스트링 처리 알고리즘 | 패턴 매칭 알고리즘 (0) | 2022.11.10 |
| [알고리즘] 스트링 처리 알고리즘 | 보이어 무어 알고리즘 (0) | 2022.11.10 |